
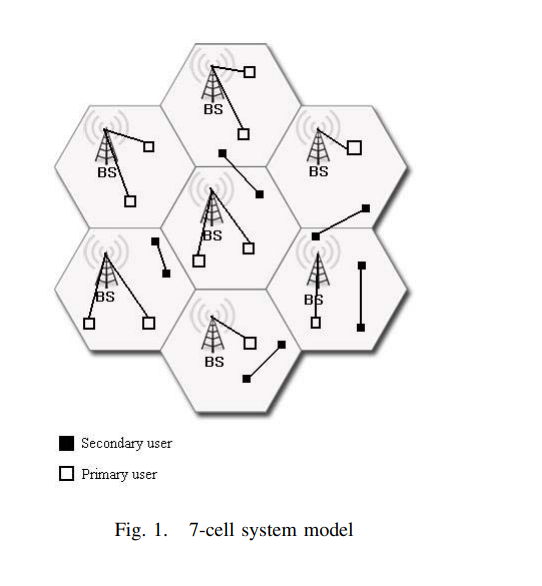
Distributed admission and power control for cognitive radios in spectrum underlay networks
In this paper we investigate admission control and power allocation for cognitive radios in an underlay network. We consider the problem of maximizing the number of supported secondary links under their minimum QoS requirements without violating the maximum tolerable interference on primary receivers in a cellular network. An optimal solution to our problem is shown in previous works to be NP-hard. We propose an efficient distributed algorithm with reasonable complexity that provides results close to the optimum solution without requiring neither a large amount of signaling nor a wide range of
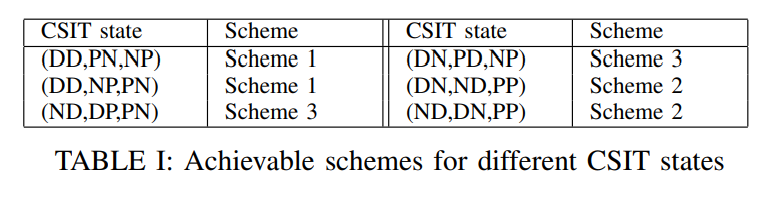
A degrees of freedom-optimal scheme for SISO X channel with synergistic alternating CSIT
In this paper, the degrees of freedom (DoF) of the two-user single input single output (SISO) X channel are investigated. Three cases are considered for the availability of channel state information at the transmitters (CSIT); perfect, delayed, and no-CSIT. A new achievable scheme is proposed to elucidate the potency of interference creation-resurrection (IRC) when the available CSIT alternates between these three cases. For some patterns of alternating CSIT, the proposed scheme achieves 4/3 DoF, and hence, coincides with the information theoretic upper bound on the DoF of the X channel with
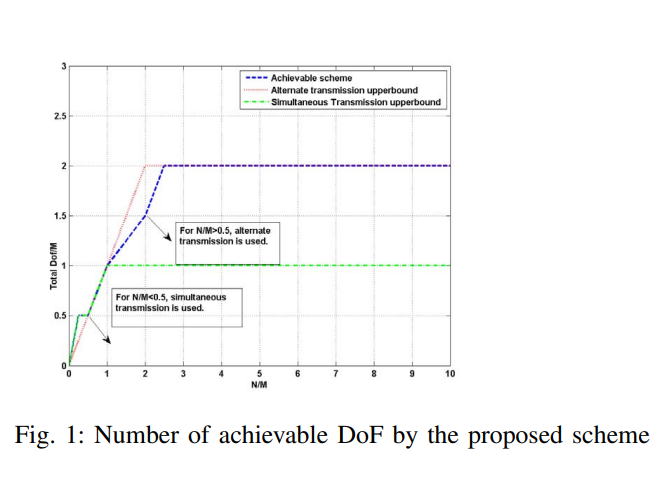
Alternate versus simultaneous relaying in MIMO cellular relay networks: A degrees of freedom study
In this paper, a two-hop cellular relay network consisting of two source-destination pairs equipped with M antennas is considered where each source is assisted by two decode-and-forward relays operating in half-duplex mode and the relays are equipped with N antennas. The DoF of the system is investigated for both simultaneous and alternate relaying configurations. For each relay configuration, an outer bound on the degrees of freedom (DoF) is developed. A new achievable scheme is proposed that meets the upper bound on the maximum DoF for all values of M andN except for M
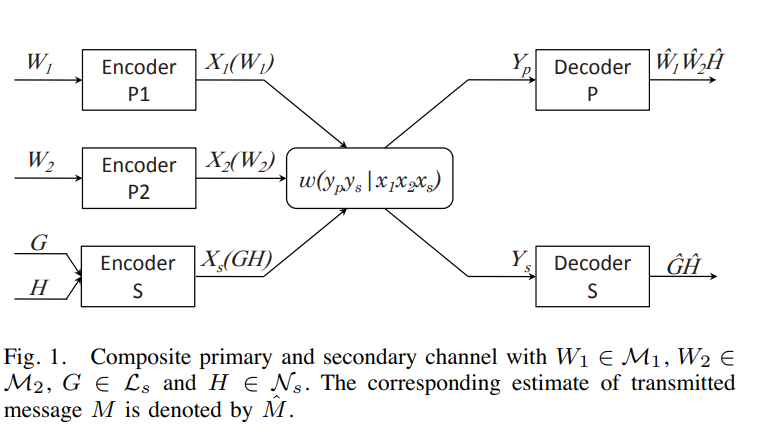
An achievable rate region for a primary network shared by a secondary link
We consider a multiple access primary network with N transmitters. A secondary link of one transmitter and a corresponding receiver causes interference to the primary network. An achievable rate region for the primary network and the secondary link is obtained given the following mode of operation. The secondary transmitter employs rate-splitting so that the primary receiver can decode part of the secondary's signal and cancel it. The secondary receiver, on the other hand, treats primary interference as noise. Given a Gaussian channel model, we investigate the effect of rate-splitting on the
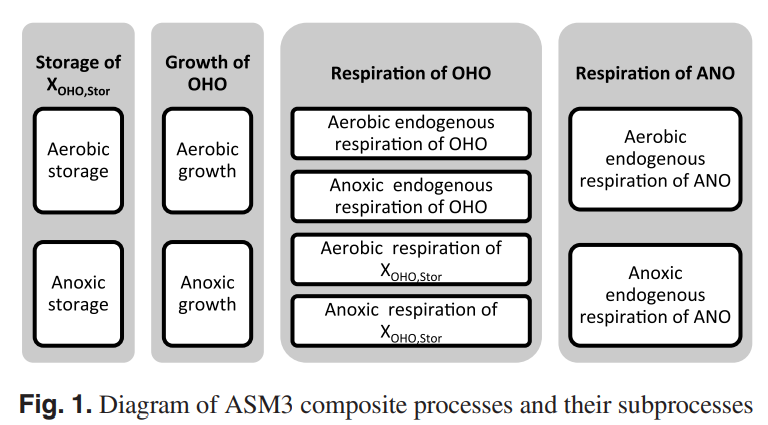
Comparison and database development of four recent ASM3 model extensions
In the last decade, many Activated Sludge Model No. 3 (ASM3) extensions were proposed to adopt new concepts such as simultaneous storage and growth of heterotrophic organisms and two-step nitrification-denitrification processes. From these ASM3 model extensions, four are included in this study: ASM3 with two-step nitrification-denitrification, ASM3 for simultaneous autotrophic and heterotrophic storage-growth, ASM3 extension for two-step nitrification-denitrification, and ASM3 for simultaneous storage-growth and nitrification-denitrification. The four models are analyzed and compared to the
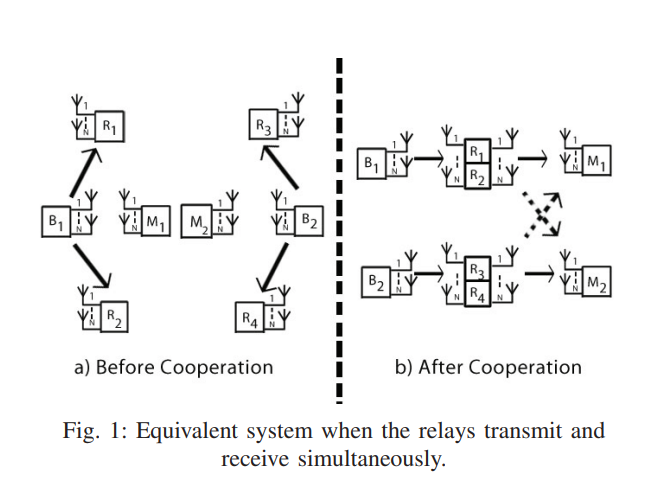
Alternate relaying and the degrees of freedom of one-way cellular relay networks
In this paper, a cellular relaying network consisting of two source-destination pairs, and four decode-and-forward relays operating in half-duplex mode is considered. Each source is assisted by two relays and all nodes are equipped with N antennas. In order to compensate for the loss of capacity by a factor of half due to the half-duplex mode, an alternate transmission protocol among the two relays is proposed. An outer bound on the degrees of freedom (DoF) of this system is developed. A constructive proof of achievability based on two different schemes is provided. Aligning the inter-relay

Alignment of minisatellite maps based on run-length encoding scheme
Subsequent duplication events are responsible for the evolution of the minisatellite maps. Alignment of two minisatellite maps should therefore take these duplication events into account, in addition to the well-known edit operations. All algorithms for computing an optimal alignment of two maps, including the one presented here, first deduce the costs of optimal duplication scenarios for all substrings of the given maps. Then, they incorporate the pre-computed costs in the alignment recurrence. However, all previous algorithms addressing this problem are dependent on the number of distinct

(562bb) Semi-pilot plant for tertiary treatment of domestic wastewater using algal photo-bioreactor, with artificial intelligence
This study attempted to investigate the removal of biological oxygen demand (BOD), chemical oxygen demand (COD), total suspended solids (TSS), ammonia-nitrogen (NH4-N), and total phosphorus (TP) from secondary treated domestic wastewater using algal photo-bioreactor. A semi-pilot plant was constructed and operated for 112 days under continuous flow conditions at Zenin wastewater treatment plant, Giza, Egypt (WWTP) which consists of an algal photo-bioreactor with an effective volume of 188 litters and a lamella settler. The removal of the studied parameters was studied at different hydraulic

(670d) Study the degradation and adsorption processes of organic matters from domestic wastewater using chemically prepared and green synthesized nano zero-valent iron
Advanced oxidation processes (AOPs) using chemically prepared and green synthesized nano zero-valent iron (nZVI) has proved to be effective in removing organic contaminants. The green synthesized nano iron (GT-nZVI) was prepared by using extracted black tea reducing agent. The prepared nZVI particles were characterized using X-ray powder diffraction (XRD), scanning electron microscopy (SEM), and Energy Dispersive X-ray Analysis (EDAX) analysis. The main purpose of this study is to compare between chemically prepared nZVI and GT-nZVI in the biological oxygen demand (BOD) removal efficiency from
Optimum Scheduling of the Disinfection Process for COVID-19 in Public Places with a Case Study from Egypt, a Novel Discrete Binary Gaining-Sharing Knowledge-Based Metaheuristic Algorithm
The aim of this paper is to introduce an improved strategy for controlling COVID-19 and other pandemic episodes as an environmental disinfection culture for public places. The scheduling aims at achieving the best utilization of the available working day-time hours, which is calculated as the total consumed disinfection times minus the total loosed transportation times. The proposed problem in network optimization identifies a disinfection group who is likely to select a route to reach a subset of predetermined public places to be regularly disinfected with the most utilization of the